CPU Controller
CPU utilization is another area where implementing cgroup2 architecture can make major resource control improvements. This section describes the concepts and strategies needed to get started controlling CPU resources with cgroup2, and includes a case study showing how the CPU controller is used in production today to control and monitor CPU usage in Facebook's data centers.
Overview
When enabled, the CPU controller regulates distribution of CPU cycles and enforces CPU limits for its child cgroups. It implements both weight and absolute bandwidth limit models for normal scheduling policy, and an absolute bandwidth allocation model for realtime scheduling policy.
Warning: The CPU controller can only be enabled when all realtime processes are in the root cgroup, as cgroup2 doesn't yet support control of realtime processes. Be aware that system management software may already have placed realtime processes into non-root cgroups during the system boot process, so these processes may need to be moved to the root cgroup before the CPU controller can be enabled.
Interface files
Like the other cgroup2 controllers, the CPU controller creates a corresponding set of interface files in its child cgroups whenever it's enabled. You adjust the distribution of CPU resources by modifying these interface files, often in a Chef recipe or in the configuration for another deployment tool. Other interface files allow you to query and monitor a cgroup's stats.
Be sure to see the canonical cgroup v2 reference documentation for additional details on the CPU controller files.
| File | Description |
|---|---|
cpu.stat | This file exists whether the controller is enabled or not. It always reports the following three stats:
|
cpu.weight | A single value file which exists on non-root cgroups, used to set a proportional bandwidth limit. The default is 100. The weight is in the range [1, 10000]. |
cpu.weight.nice | This is an alternative interface for cpu.weight and allows reading and setting weight using the same values used by nice. The default is 0. The nice value is in the range [-20, 19]. Because the range is smaller and granularity is coarser for the nice values, the read value is the closest approximation of the current weight. |
cpu.max | The maximum bandwidth limit. It's in the following format: $MAX $PERIOD which indicates that the group may consume up to $MAX in each $PERIOD duration. Using max for $MAX indicates no limit. If only one number is written, $MAX is updated. The default is max 100000. |
cpu.pressure | A measure of CPU pressure. See discusssion below. |
Measuring CPU pressure with PSI
The CPU controller tracks pressure stall information (PSI) in the cpu.pressure file.
It shows one statistic: some, which is the percentage of elapsed walltime in which one or more tasks are waiting for a CPU to become available.
some avg10=2.04 avg60=0.75 avg300=0.40 total=157656722
The first three numbers are running averages over approximately the last 10 seconds, 1 minute, and 5 minutes, respectively.
The total value gives the absolute stall time in microseconds. This allows detecting latency spikes that might be too short to sway the running averages.
See the PSI documentation for more details about PSI metrics.
Case Study: Optimizing CPU utilization for Facebook's Laser service
To develop strategies for improving CPU utilization, Facebook's Resource Control team partnered with infrastructure teams around the organization. This section describes a case study using the cgroup2 CPU controller that resulted in greater control over CPU resources for an internal data aggregation service called Laser.
Overview
Laser is a data publishing service that processes high-bandwidth data streams into an indexible database. These data streams are comprised in large part of log data from a service called Scribe, a distributed messaging system for collecting and aggregating high-volume message data with low latency, widely used in Facebook's production environment.
Laser reads, parses, indexes, and stores Scribe data and serves it to various teams within Facebook. There are hundreds of separate Laser instances for different domains, stacked across a pool of hosts, with dozens of instances per host. Each instance reads the data in its own Scribe pipe and feeds it into the matching Laser index. Every Laser instance exists in its own container, using Facebook's internal containerization solution Tupperware, with one Tupperware job per Laser instance.
Problem
Prior to implementing cgroup2, the Laser team experienced frequent performance issues due to one Laser instance dominating the CPU and starving other threads.
An additional problem was that when hosts in the pool get busy, Laser instances are migrated to other hosts: Due to the need to process backlogs and other items on the new machine, CPU usage would often spike even more, taking all cycles of the host and leading to more CPU control problems.
Moreover, because Laser instances are colocated, the Laser team needed a way to guarantee the amount of CPU resources for each instance while isolating any noisy neighbors.
Solution
Each Laser instance uses Tupperware, and each Tupperware instance has the CPU controller enabled. Laser uses the CPU controller in each Tupperware instance to distribute CPU resources more equitably and guarantee the amount of CPU resource for each Laser instance.
The CPU controller in this case uses proportional control (not maximum bandwidth limit): Thus, the CPU settings for each instance are set in cpu.weight.
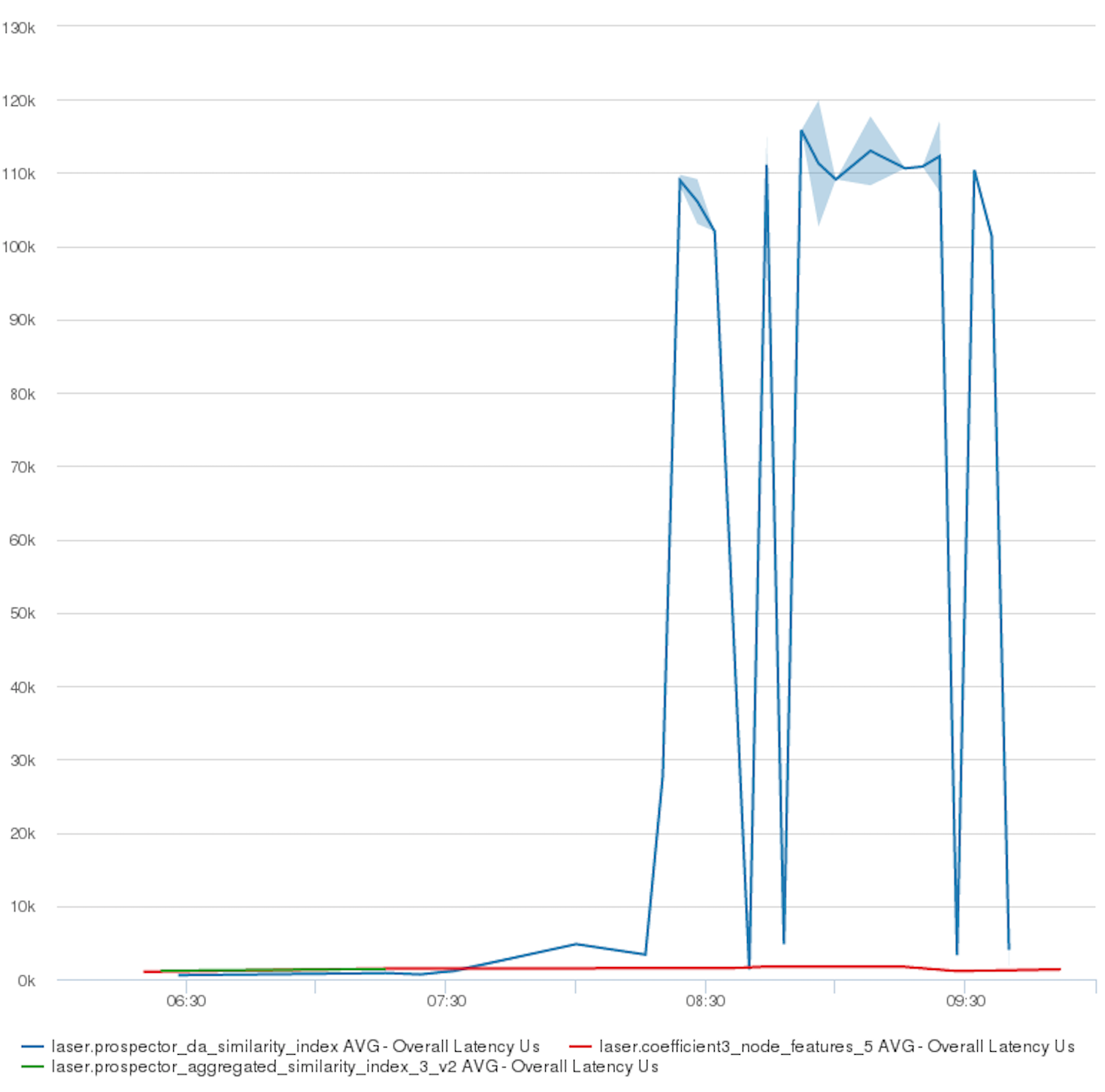
The chart below shows how CPU was distributed as a result of the settings in the Tupperware jobs' cpu.weight: Latency spikes for the Laser job shown by the blue line, while CPU is guaranteed to the other jobs, whose latency remains low.