fbtax2: Putting it All Together
Throughout these docs, we've looked at a running case study for the fbtax2 project that illustrates key principles of resource control using cgroup2 and related tools. This page summarizes that strategy, and extracts principles that can be generalized to a variety of use cases and scenarios. It also shows test results that demonstrate the resource control gains that resulted from implementing a comprehensive resource control strategy.
Strategy summary
The fbtax2 project provides a working demonstation of a transparent and comprehensive resource control framework—isolating and protecting the main workload from lower-priority support applications.
This fbtax2 example can also be easily expanded to cover a variety of other scenarios, such as protecting an interactive workload from side-loaded batch workloads, and many other possible cases where critical workloads require resource isolation.
The following sections summarize the settings and strategies used for each cgroup controller and related tools, and show the resource control and utilization results that fbtax2 brought to Facebook's data centers.
Memory
The fbtax2 memory strategy uses the combination of memory.min and memory.low for memory protection. Compared to memory.high/memory.max, they have the following benefits:
- They are work-conserving. No memory will be lying around unused due to resource limits.
- They proportionally regulate memory reclaim. Memory reclaim pressure is distributed in proportion to the amount of overage above a given cgroup's
memory.min/memory.lowprotection. For example, if two peer cgroups A and B are currently at 3G, but A has 2G ofmemory.lowprotection while B doesn't, B will experience three times higher reclaim pressure. This makesmemory.minandmemory.lowa lot easier to use and more useful thanmemory.high/memory.maxsince the configurations have gradual effects and can be ballparked.
Memory overcommit—promising more memory for processes than the total system memory—is also a crucial technique for cgroup memory control. Although demand may occasionally exceed the available system memory, the savings from hosting more apps on one system outweigh the disadvantages of occasional OOM conditions.
See the memory controller strategies page for more details.
Swap
As discussed in a previous section of the fbtax2 case study, swap can play a key role in resource control strategies.
Historically, swap has been considered problematic, especially with hard disks. But because of the way oomd uses PSI to detect excessive IO time and intervenes to kill processes before thrashing or lockups occur, swap turned out to be effective in this case.
Swap provides the following benefits:
- Better use of memory
- Allows memory pressure to build up gracefully, avoiding crashes due to sudden spikes
If swap is not used, all anon memory is memlocked. For fbtax2, swap was enabled everywhere except for the main workload.
IO
io.latency is the main knob used for IO protection. With io.latency you can set a target latency in milliseconds which is periodically checked against the real latency, to ensure that real latency is not exceeded. If it does exceed real latency, IO from other cgroups is constrained to bring the target latency back down.
The experimentation for the fbtax2 project indicated that setting io.latency to several times higher than the usual expected latency as a starting point, especially for hard disks, produced the best results.
io.latency is set only on the top level slices of the cgroup hierarchy. High priority slices (e.g., workload.slice) get 50ms and low priority slices (e.g., system.slice) get 75ms, thereby prioritizing the main workload. For rotating disks, 50ms hits a nice balance where low priority slices don't get punished excessively, but still trigger fairly reliably when high priority slices start hurting. The low priority value of 75ms decides how severely those slices are punished when high priority cgroups start missing the target latency. This setting isn't too sensitive - 60ms or 100ms would also likely work fine.
See the IO controller page for more details.
CPU
The fbtax2 project leverages the CPU control on Tupperware, Facebook's internal containerization solution. Each Tupperware instance has the CPU controller enabled; the settings ensure equitable distribution of CPU resources, and guarantee the amount of CPU resource for each instance.
The CPU settings for each instance are set in cpu.weight, using proportional control instead of maximum bandwidth limit (which is set in cpu.max).
See the CPU controller page for more details.
cgroup2 hierarchy
The main goals the hierarchy addresses are:
- Preventing non-critical services from negatively impacting critical services through resource usage.
- Gracefully degrading in the case that a machine is unable to sustain nominal workload.
- Avoiding unnecessary performance degradations or heavy operational cost from these changes.
The diagram shows the hierarchy and the settings as determined through the steps described above.
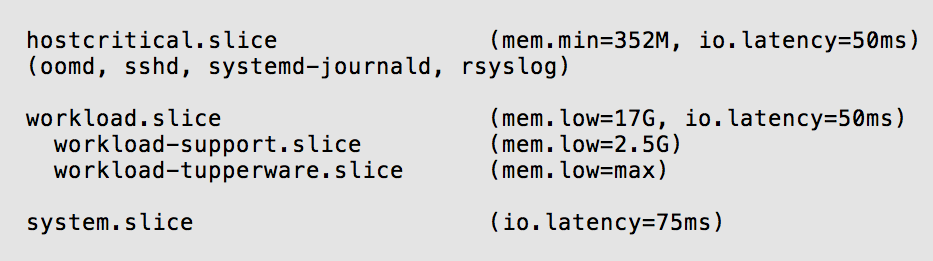
See Creating and organizing cgroups for more details.
Related tools and components
The following sections discuss the role of PSI metrics and oomd in the fbtax2 strategy.
PSI metrics
PSI metrics play a critical role in several different capacities as part of the fbtax2 resource control strategy:
- Provides insight into whether a given workload has sufficient memory to complete.
- Provides insight into general system memory use, instead of using repeated trial and error approaches to determine effective memory settings.
- Acts as a trigger for oomd's out-of-memory process killing.
See the PSI pressure metrics page for more information.
oomd
oomd plays three roles.
- Resolving memory overcommit situations in a proactive and context-aware way (don't kill a process just because it's big).
- Provide a measure of quality of service for system services that can be retried. If heavily thrashing, it's better to kill a process and let it retry, rather than prolong the misery.
- Helping when kernel resource isolation starts breaking down. The kernel's resource isolation is still far from perfect and there are situations where it fails to sufficiently protect the main workload, for example, due to priority inversions through certain locking constructs. oomd monitors workload health through resource pressure metrics and helps with untangling these conditions.
fbtax2 test results
This following sections show the results of the strategic decisions described above when a system is exposed to different stressors, comparing the fbtax2 setup to a base setup.
Memory leaks in system.slice
The chart shows the results of simulating a memory leak in system.slice. These tests simulate a support application in system.slice continuously leaking memory. A Python script is run in its own service under system.slice and keeps allocating memory at different paces until it reaches 20G.
10MB/s growth simulation
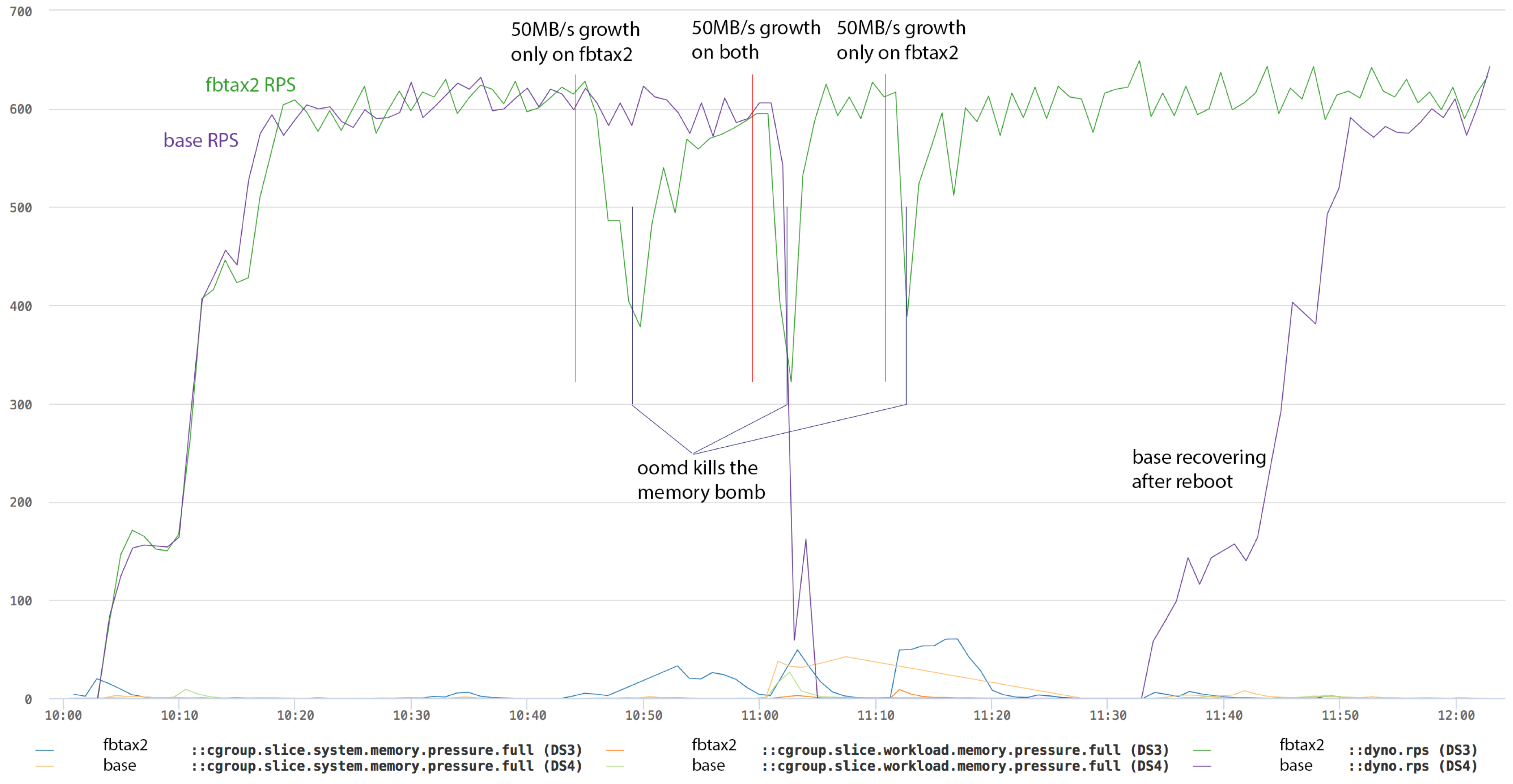
- On fbtax2, while requests-per-second (rps) dips somewhat, the memory and IO control keeps the main workload afloat and eventually oomd decides that the situation in
system.sliceis unsustainable, kills the service leaking memory, and the machine recovers. The test is repeated three times with about the same results. - On the base setup, once memory consumption grows beyond a certain point on the first run, the machine enters deep thrashing and never recovers without a reboot.
The lines at the bottom show memory pressures in workload.slice and system.slice for both machines. On fbtax2, while the system's pressure rises significantly faster, workload.slice's barely increase throughout the tests. On the base setup, workload and system pressures rise together before the whole system enters deep thrashing.
The multiple jagged dips in fbtax2's rps during the pressure periods are primarily caused by oomd picking the wrong victims based on IO pressure, which only temporarily mitigates the problem. While this isn't critical, we should be able to improve the behavior by targeting IO pressure kills better.
50MB/s growth simulation
The results are the same for 50MB/s growth as the 10MB/s tests except for the accelerated timings.
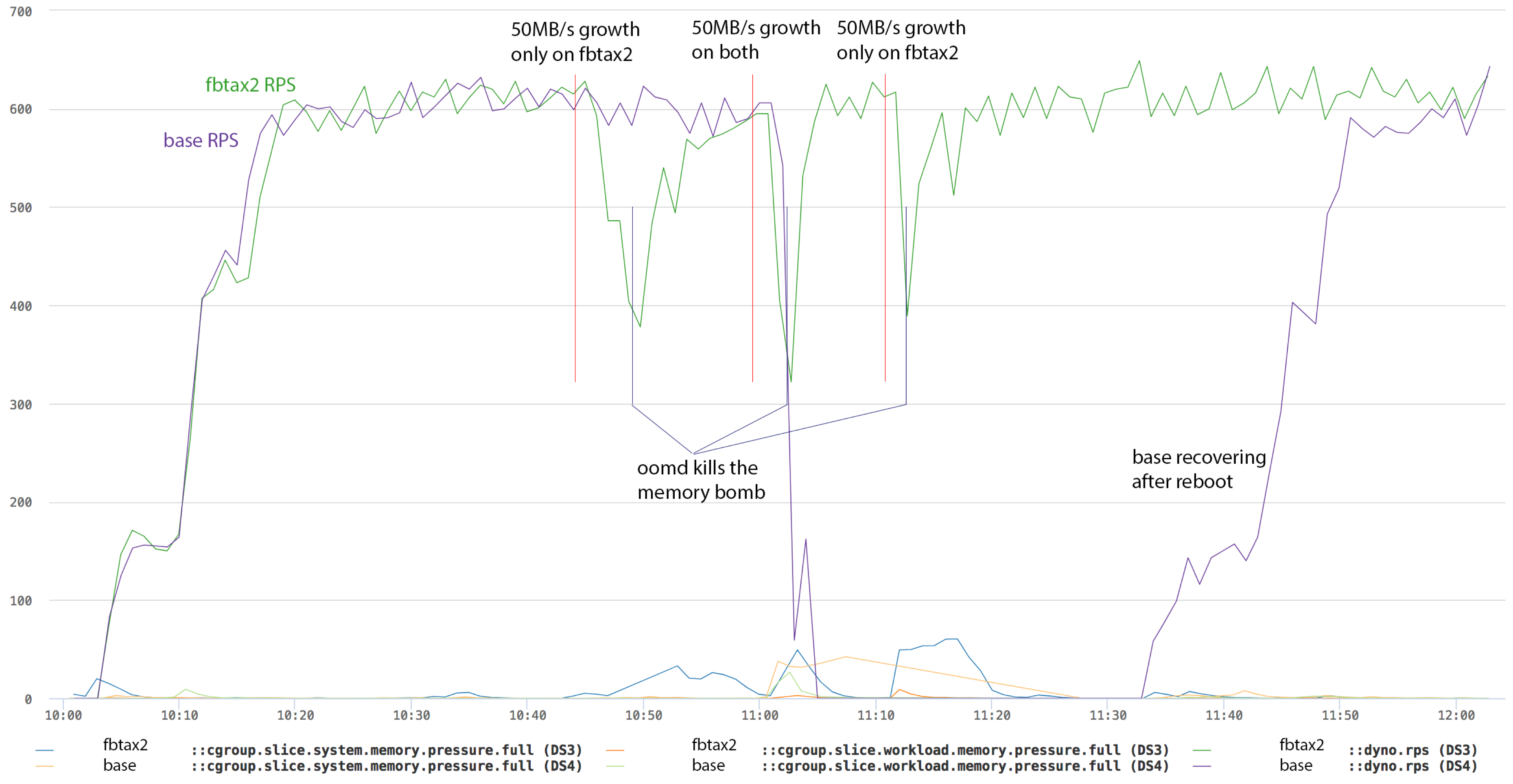
- On fbtax2, 50MB/s growth is started three times. The rps suffers a bit but resource control holds it up and oomd steps in to resolves the situation.
- On base, 50MB/s growth is started once. The system enters deep thrashing almost immediately and never recovers without a reboot.
100MB/s growth simulation
This chart shows 100MB/s growth:
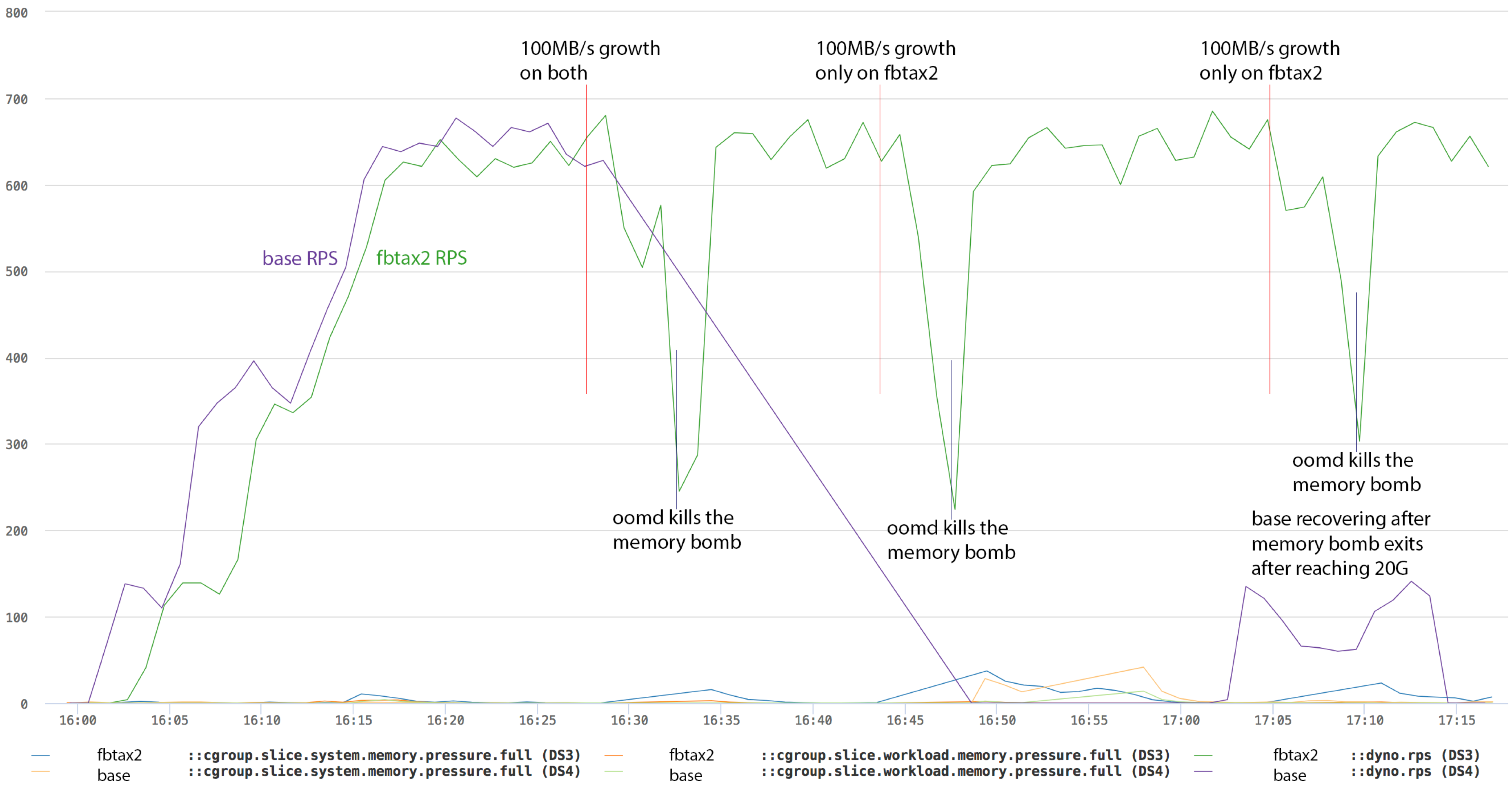
- On fbtax2, except for the deeper stalls, the same as before - the memory leak is started three times and the machine and workload survive mostly intact.
- On base, the system almost immediately enters deep thrashing on the first run. This time, hhvm gets OOM-killed by the kernel and the memory bomb successfully allocates 20G and exits. The machine slowly recovers afterwards.
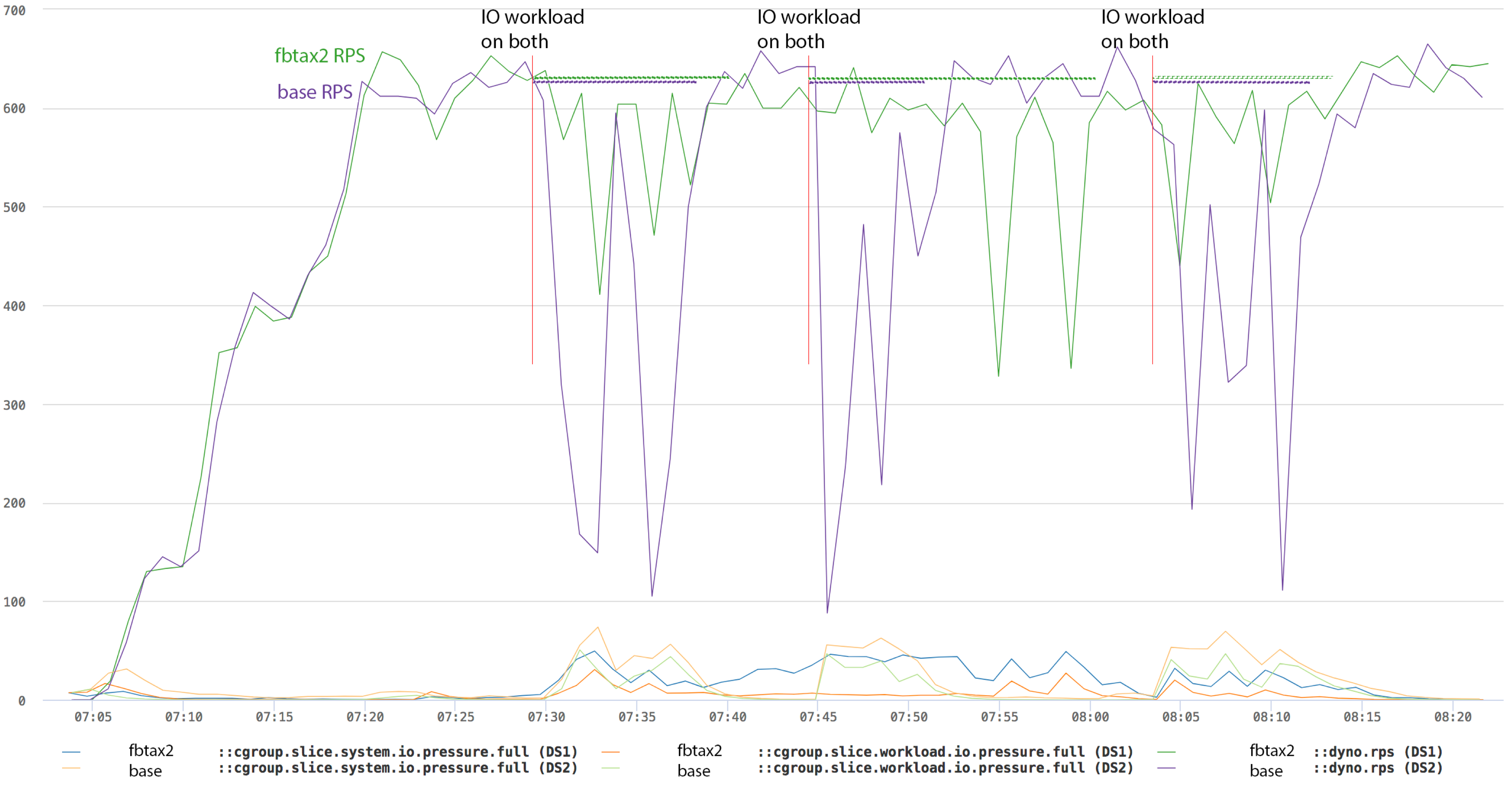
IO storm in workload.support.slice
This test simulates heavy IO load in system.slice. The test scripts untars three copies of a kernel source tree, touches all of them and deletes them.
Result summary
The results show that the differences between fbtax2 and base are striking when the system is facing runaway resource problems. With fbtax2, all that happens is minor temporary service quality degradation. Without it, the whole system can easily be lost, requiring a lengthy recovery. This protection comes at essentially no cost—there's no on-going overhead to pay.
While the protections are great, there still are dips in rps. They come from:
- The kernel virtual memory management can't know which pages are hot without causing faults. When there is no memory pressure, the kernel gradually loses knowledge of the current working set. As memory pressure rises, the kernel has to rebuild the knowledge by faulting out pages and then letting the hot pages re-establish themselves. This contributes to contained spikes even in the protected workload. The effect is exaggerated by slow hard disk.
- Hard disks are slow and nominally over-subscribed. In other words, support applications can't run acceptably without affecting
workload.sliceat least temporarily. The resource protection configuration has to allow for such fluctuations. - Resource isolation isn't perfect. cgroup2 controllers have inherent and implementation-specific limitations and there still are remaining priority inversion issues which can transfer high resource pressure in
system.slicetoworkload.slice.
Most are either directly caused by, or greatly exaggerated by, the slow performance of hard disks. Testing has begun on machines with SSDs and the following chart shows the preliminary results.
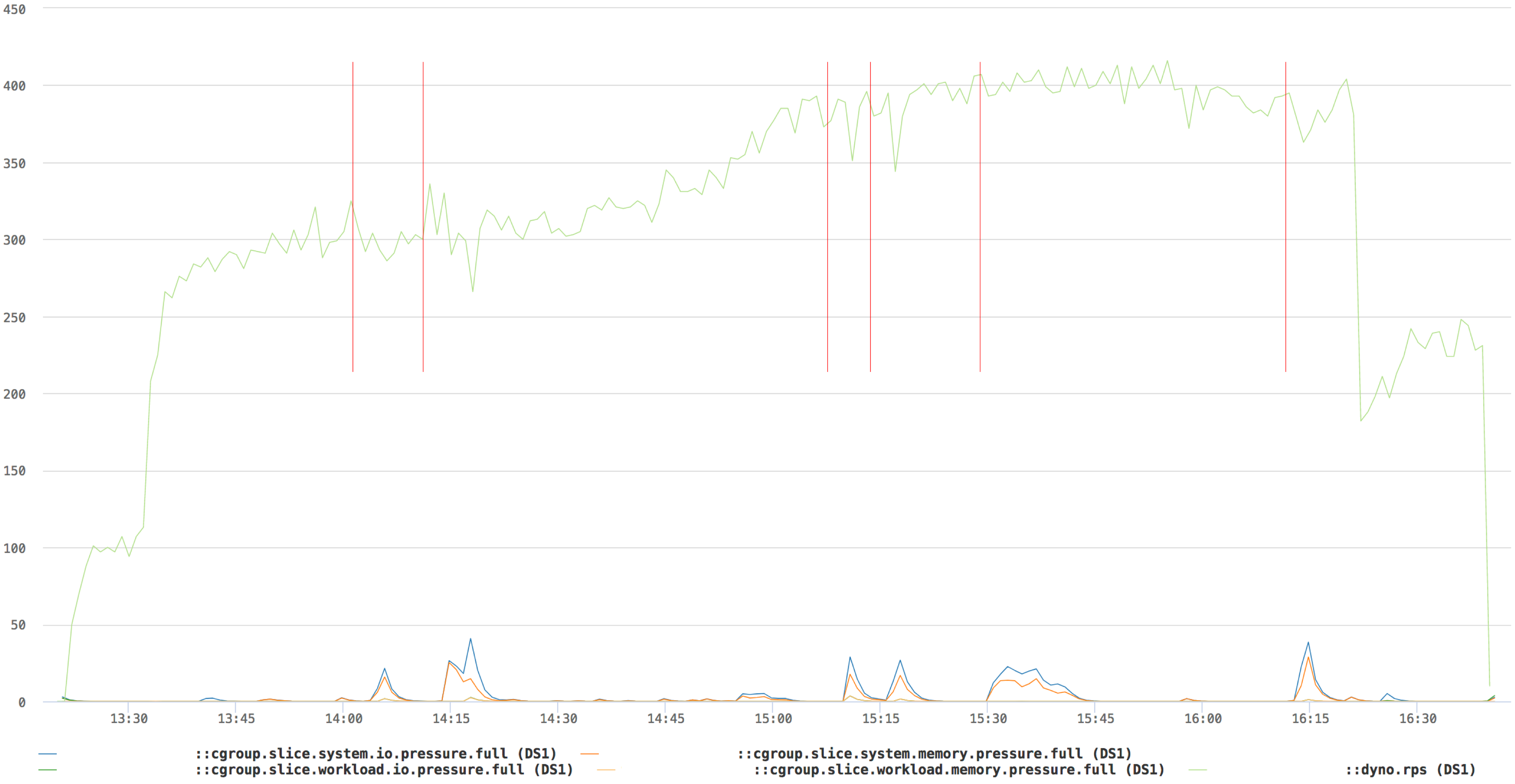
The red marker lines are 50MB/s memory leaks being started on the machine. Memory and IO protections can work a lot better on a SSD and bias both memory and IO pressures almost perfectly between workload.slice and system.slice - the former stays on the floor while the latter flares up. HHVM is hardly affected by the memory leak in system.slice and the system can sustain the state as long as swap space available. On swap depletion, oomd kicks in and cleans up.