Memory Controller Strategies and Tools
The following sections describe methods and tools that together comprise a consistent architectural approach to increasing fleet-wide memory utilization.
Memory overcommit
Overcommitting on memory—promising more memory for processes than the total system memory—is a key technique for increasing memory utilization. It allows systems to host and run more applications, based on the assumption that not all the assigned memory will be needed at the same time. Of course, this assumption isn't always true; when demand exceeds the total memory available, the system OOM handler tries to reclaim memory by killing some processes.
These inevitable memory overflows can be expensive to handle, but the savings from hosting more services on one system outweigh the overhead of occasional OOM events. With the right balance, this scenario translates into higher efficiency and lower cost.
Pressure-based load shedding
Load shedding is a technique to avoid overloading and crashing a system by temporarily rejecting new requests. The idea is that all loads will be better served if the system rejects a few and continues to run, instead of accepting all requests and crashing due to lack of resources.
In a recent test, a team at Facebook that runs asynchronous jobs, called Async, used memory pressure as part of a load shedding strategy to reduce the frequency of OOMs.
The Async tier runs many short-lived jobs in parallel. Because there was previously no way of knowing how close the system was to invoking the OOM handler, Async hosts experienced excessive OOM kills.
Using memory pressure as a proactive indicator of general memory health, Async servers can now estimate, before executing each job, whether the system is likely to have enough memory to run the job to completion. When memory pressure exceeds the specified threshold, the system ignores further requests until conditions stabilize.
The chart shows how async responds to changes in memory pressure: when memory.full (in orange) spikes, async sheds jobs back to the async dispatcher, shown by the blue async_execution_decision line.
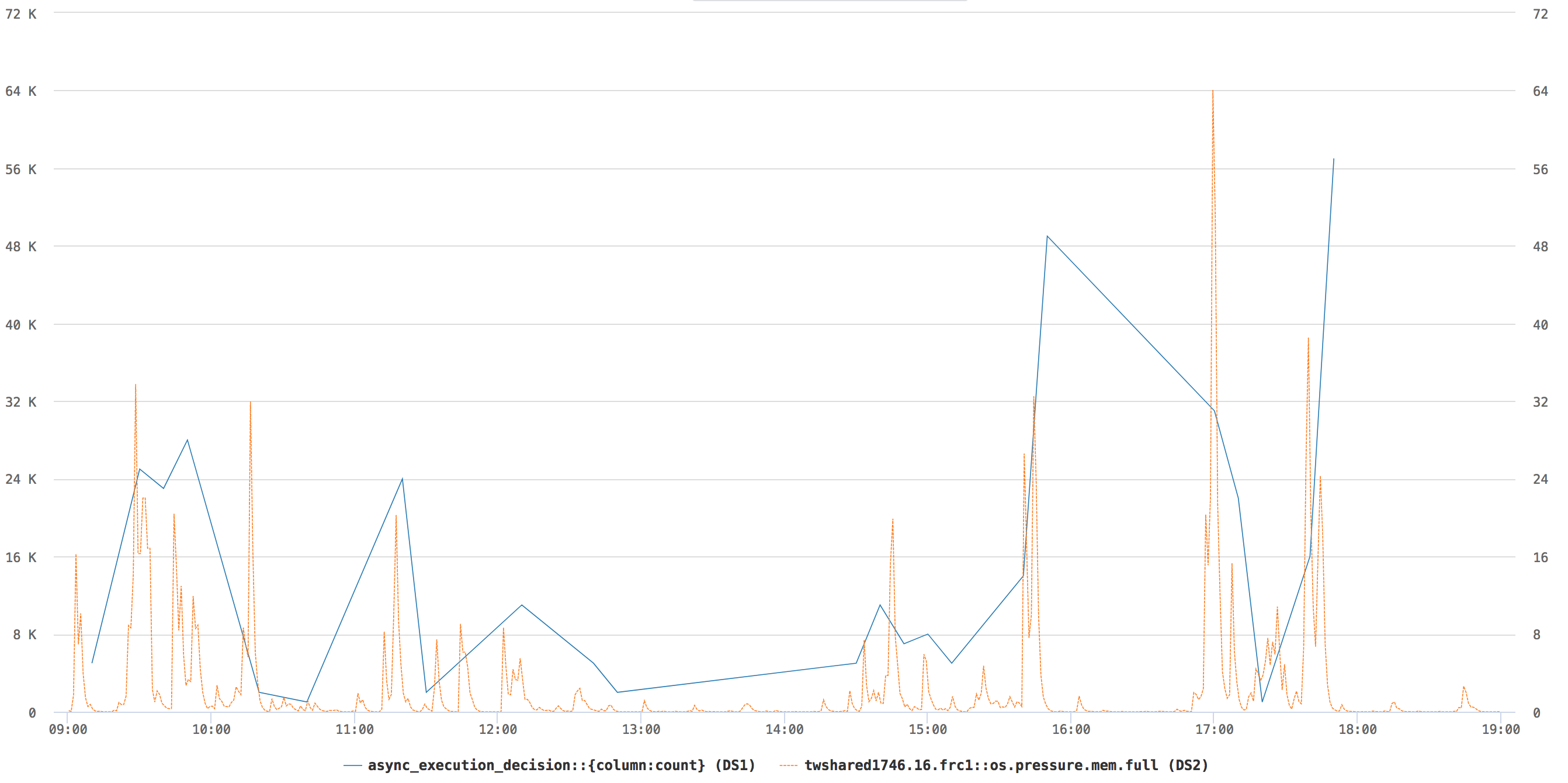
The results were signifcant: Load shedding based on memory pressure decreased memory overflows in the Async tier and increased throughput by 25%. This enabled the Async team to replace larger servers with servers using less memory, while keeping OOMs under control.
oomd - memory pressure-based OOM
oomd is a new userspace tool similar to the kernel OOM handler, but that uses memory pressure to provide greater control over when processes start getting killed, and which processes are selected.
The kernel OOM handler’s main job is to protect the kernel; it’s not concerned with ensuring workload progress or health. Consequently, it’s less than ideal in terms of when and how it operates:
- It starts killing processes only after failing at multiple attempts to allocate memory, i.e., after a problem is already underway.
- It selects processes to kill using primitive heuristics, typically killing whichever one frees the most memory.
- It can fail to start at all when the system is thrashing: memory utilization remains within normal limits, but workloads don't make progress, and the OOM killer never gets invoked to clean up the mess.
Lacking knowledge of a process's context or purpose, the OOM killer can even kill vital system processes: When this happens, the system is lost, and the only solution is to reboot, losing whatever was running, and taking tens of minutes to restore the host.
Using memory pressure to monitor for memory shortages, oomd can deal more proactively and gracefully with increasing pressure by pausing some tasks to ride out the bump, or by performing a graceful app shutdown with a scheduled restart.
In recent tests, oomd was an out-of-the-box improvement over the kernel OOM killer and is now deployed in production on a number of Facebook tiers.
Case study: oomd at Facebook
See how oomd was deployed in production at Facebook in this case study looking at Facebook's build system, one of the largest services running at Facebook.
oomd in the fbtax2 project
As discussed previously, the fbtax2 project team prioritized protection of the main workload by using memory.low to soft-guarantee memory to workload.slice, the main workload's cgroup. In this work-conserving model, processes in system.slice could use the memory when the main workload didn't need it.
There was a problem though: when a memory-intensive process in system.slice can no longer take memory due to the memory.low protection on workload.slice, the memory contention turns into IO pressure from page faults, which can compromise overall system performance.

Because of limits set in system.slice's IO controller (which we'll look at in the next section of this case study) the increased IO pressure causes system.slice to be throttled. The kernel recognizes the slowdown is caused by lack of memory, and memory.pressure rises accordingly.
oomd monitors the pressure, and once it exceeds the configured threshold, kills one of the processes—most likely the memory hog in system.slice—and resolves the situation before the excess memory pressure crashes the system. This behavior